Record high temperatures forecast for the UK - worrying trends, but it should not be a physiological problem.
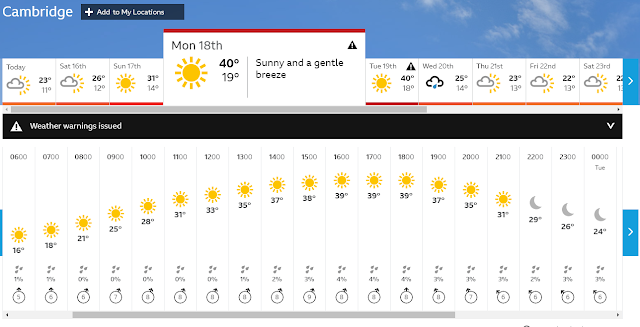 |
| BBC weather predicts highs of 40 degrees C early next week |
There seems little doubt that the frequency of 'record high temperatures' in the UK is increasing - our last record was set in July, 2019 and it now looks like that might be broken by more than 1 degree C next week. To have such a large jump in record temperatures within such a short space of time is unusual and worrying too. For sure this is caused by a weather pattern dragging hot air up from southern Europe just at the point at which they are experiencing record temperatures, so it is hard to claim that it is a result of 'average' temperature rises, but the warmer the World gets the more likely these events are going to be.
From a physiological point of view these temperatures are not yet problematic - or at least they would not be if we were properly prepared and therein lies the problem. Just as a small flurry of snow in Winter stops transportation these mini-heat waves also cause problems in the UK whereas in other countries such temperatures would barely raise an eyebrow. The problem is illustrated by the BBC weather forecast with temperatures ramping up from and back down to the low 20s with a peak of 40 for just a couple of days. It is entirely possible to physiologically adapt (acclimate) to the heat, but it takes longer than a couple of days to do so. By Monday when we expect the high temperatures, those who don't exercise, live in cool indoor environments and therefore have little ability to sweat will face a potential thermoregulatory problem. The problem is that radiant heat loss requires a cool environment - or at least one cooler than core body temperature. By the time the temperature is up at 40 degrees C radiant heat loss is useless - the only way of losing the heat we produce (even at rest) is by evaporation. Of course breathing carries away some heat, but not enough: we need to sweat. But, just like you can't suddenly grow strong arm muscles, you can't suddenly grow big sweat glands either. Sweating takes practice. If you don't regularly sweat then your maximal sweating rate will be low. Advice to drink plenty of water will not help as much as you might think - drinking won't promote sweating. Drink if you are thirsty is much better advice.
So, if you do daily exercise, enough to get hot and sweat, you are probably (like me) sitting quite comfortably and looking forward to the warm weather. You will have a cooler resting core body temperature and a capacity to sweat more than enough to deal with the warm weather. But, most people either don't or can't do that amount of exercise and will struggle to raise much of a sweat. Even people who consider themselves to be 'healthy-fit' may fall into this category. About 6 years ago my wife came into the lab to be a subject for a 'sweating' experiment. She sat on an exercise bike and pedalled whilst we measured her core body temperature rise to 39 degrees C. She went red, very red - but, not a drop of sweat. It wasn't that she was dreadfully unfit or overweight - it was just that she never worked hard enough to induce any sweating. Being able to sweat takes training, and by training I mean getting hot enough to need to sweat. There are essentially two ways of doing this - either generate the heat internally by doing exercise, or use external heat (e.g. hot baths or saunas). My wife decided to take-up running and did the wonderful NHS couch-to-5km and now runs (albeit rather irregularly).
There are many strategies to stay cool and most of them are blindingly obvious: reduce activity levels (internal heat generation), stay in a cool environment and use water (applied directly to the skin) to mimic sweating. A wet cloth and a draught is more than enough to stay cool when humidity levels are relatively low. Hot weather and high humidity is a different beast. I recall, as a youngster, sitting very comfortably in a sauna (probably about 100 degrees C - my father built one in our garage) and putting quite a lot of water on the stones. The effect was immediate pain as the humidity rose rapidly causing a dramatic rise in skin temperature. I fled the sauna. Humid hot environments are a real physiological problem to which we don't have a solution.
You might wonder why we don't all have large sweat glands, one that don't need training to keep them big. If having large sweat glands that can produce copious amounts of sweat make Summer heat so easy to deal with, why hasn't evolution caused them to just exist in our skin all of the time? The best guess for why we have trainable sweat glands is that in the Winter sweating is a very dangerous activity - wet skin after running could easily induce hypothermia in Winter. I had not realized just how dangerous this was until I got injured about 2 miles from home one Winter whilst out running. I was dressed in several running jackets, and nicely hot, but they were soaked in sweat and I was forced to walk. I wasn't too concerned since 2 miles seemed entirely 'walkable' but, I had not factored in just how quickly body temperature can fall when you are soaking wet and heat production drops. I now run with a mobile phone and, more importantly, a foil (space) blanket.

